
Reinforcement learning example – Lunar lander & CartPole
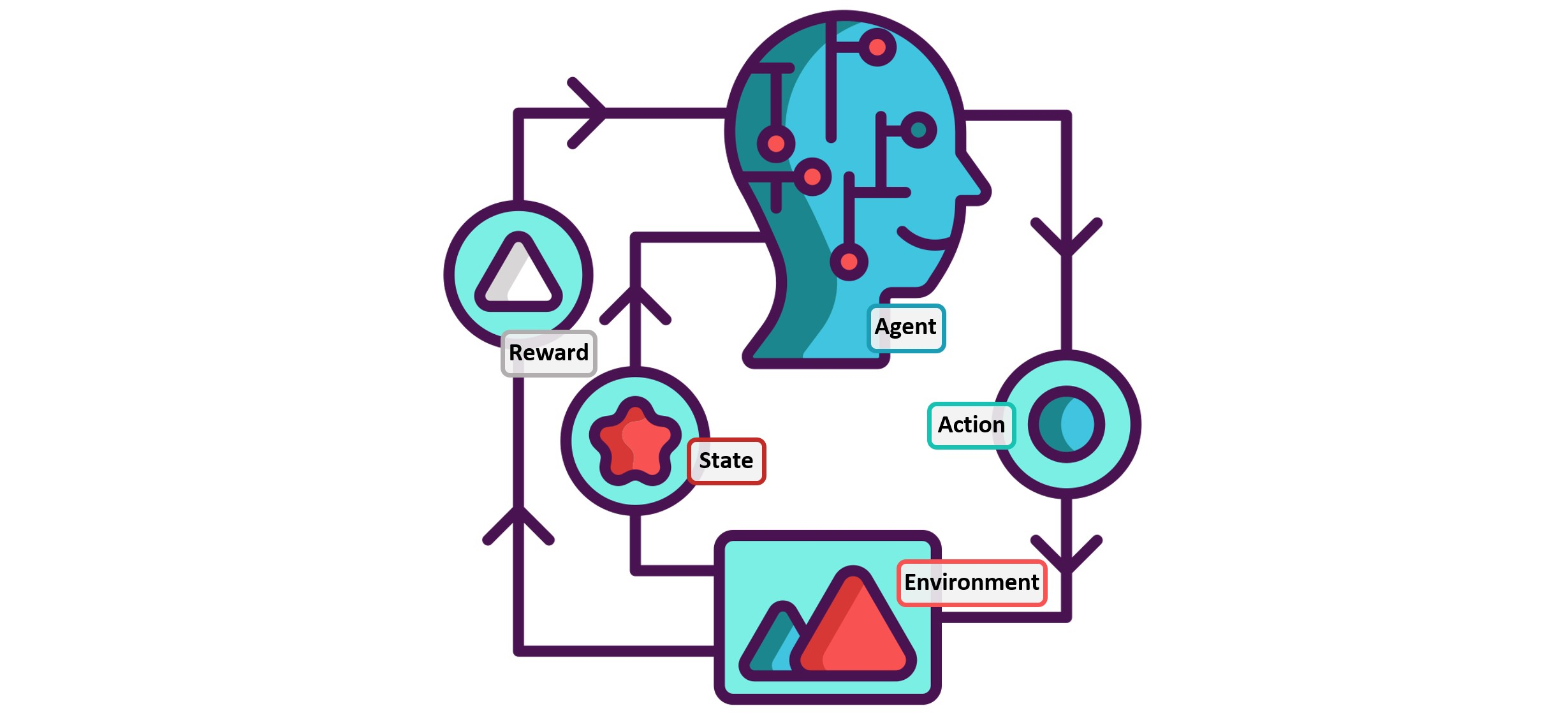
One of the most interesting applications of machine learning. Reinforcement learning is a type of machine learning that enables an agent to learn in an interactive environment by trial and error. The agent receives rewards or punishments for its actions, which helps it learn to make optimal decisions. Unlike supervised learning, where the agent is given a correct set of actions for a task, reinforcement learning uses rewards and punishments to guide the agent’s behavior. The goal is to maximize the cumulative reward over time, balancing exploration and exploitation to achieve the desired outcome. This approach is particularly useful for complex problems where the optimal solution involves a sequence of decisions, such as playing games or controlling robots.
Reinforcement learning involves several key elements, including the environment, agent, actions, states, rewards, policy, and value. The environment is the context in which the agent operates, and the agent is the decision-maker within that environment. Actions are the moves taken by the agent, which lead to changes in the state. Rewards are the feedback the agent receives for its actions, which can be positive or negative. The policy defines how the agent behaves at a given time, and the value represents the long-term benefits of different states or actions. Reinforcement learning algorithms are used to design the learning agent, update its policy, and learn from feedback. This approach has a wide range of applications, including robotics, game playing, and diagnosing rare diseases, and is particularly useful for problems that involve a series of decisions that all affect one another. Since time is of an essence, I will avoid explaining how the RL algorithm works. This article concentrates on deploying RL agents to various tasks, namely, Lunar lander and Cartpole.
Do know that you can find the code for this project in my gitHub repo as well.
p.s. We use Q Learning algorithm to implement the reinforcement learning, so we will refer to our deep neural network as DQNs
Bird’s eye view
Since we are trying to solve real-world problems, there must be some nasty dynamic systems involved to simulate what happens in our environment. Lets remember that we are not here to model real-world situations, we are here to learn RL; so lets not reinvent the wheel!
Here we use gymnasiym library to simulate real-world environments. We will use two built-in environments here, namely, “LunarLander-v2” and “CartPole-v1”. Gymnasium simply takes care of the dynamic interactions under the hood, providing outputs for every provided initial condition. But please note that for using gymnasium’s visualization (which is very fun), you have to use a linux-based machine.
pip install gymnasium
Below, you can see a description of the used environments:
CartPole-V2
- The goal is to keep the pole upright for as long as possible
- You have two actions in the action space, 0 (Go left) and 1 (Go right)
- The observation space is a ndarray with shape (4,):
- 0- Cart position [-4.8,4.8]
- 1- Cart velocity [-inf,inf]
- 2- Pole angle [-.418 rad, .418 rad]
- 3- Pole anglular velocity [-inf,inf]
- Rewards: A reward of +1 for every step taken, including the termination step, is allotted. The threshold for rewards is 475 for v1.
- Episode end: The episode ends if any one of the following occurs
- Termination: Pole Angle is greater than ±12°
- Termination: Cart Position is greater than ±2.4 (center of the cart reaches the edge of the display)
- Truncation: Episode length is greater than 500 (200 for v0)
LunarLander-v2
- The goal is to land the moon lander in a specific location
- You have four actions in the action space, 0 (Do nothing), 1 (Fire left orientation engine), 2 (Fire main engine) , 3 (Fire right orientation engine)
- The observation space is a ndarray with shape (8,):
- 0, 1: It’s (x,y) coordinates. The landing pad is always at coordinates (0,0)
- 2, 3: It’s linear velocities (xDot,yDot)
- 4: It’s angle Theta
- 5: It’s angular velocity thetaDot
- 6, 7: Two booleans l and r that represent whether each leg is in contact with the ground or not.
- Rewards:
- Is increased/decreased the closer/further the lander is to the landing pad
- Is increased/decreased the slower/faster the lander is moving
- Is decreased the more the lander is tilted (angle not horizontal)
- Is increased by 10 points for each leg that is in contact with the ground
- Is decreased by 0.03 points each frame a side engine is firing
- Is decreased by 0.3 points each frame the main engine is firing
- The episode receive an additional reward of -100 or +100 points for crashing or landing safely respectively
- An episode is considered a solution if it scores at least 200 points
- Episode end: The episode finishes if
- The crashes (the lander body gets in contact with the moon)
- The lander gets outside of the viewport (x coordinate is greater than 1)
- The lander is not awake. From the Box2D docs, a body which is not awake is a body which doesn’t move and doesn’t collide with any other body
Replay Memory Class
The bulk of our work happens in this part. Here we construct a class called ReplayMemory where takes care of the learning process. A replayMemory is an object that saves N most recent steps and helps the neural network to update its weights. Also, note that this class can be used in both environments (lunar lander and cart pole) with minimal alterations.
class ReplayMemory(object):
"""
Implement's the replay memory algorithm.
"""
def __init__(self, size) -> None:
"""
Initialize the class with a double ended queue which will contain named tuples.
"""
self.exp = deque([], maxlen=size)
self.len = len(self.exp)
We will use python’s double ended queue to save the experiences in (self.exp). This choice was made due to superiority of “deque” in the speed of appending and popping from both ends of the object. Alternatively, you could use “list” but you will need more computations with may make bottlenecks in terms of application speed.
Next, we add a method for adding new experiences. We simply use the “expandleft” method of the deque to increase out queue in size. This code is method is the backbone of the learning process, so it has to be written as efficient as possible (Next to updating the weights of the NN). Also, note that each experience that is added to the queue is a namedtuple. The named tuple should have the following keys: “state”, “action”, “reward”, “nextState” and, “done”.
def addNew(self, exp:namedtuple) -> None:
"""
Adding a new iteration to the memory. Note thate the most recent values of
the training will be located at the position 0 and if the list reaches maxlen
the oldest data will be dropped.
Args:
exp: namedtuple: The experience should be a named tuple with keys named
like this: ["state", "action", "reward", "nextState", "done"]
"""
self.exp.appendleft(exp)
self.len = len(self.exp)
Now, we know that the neural network has to be updated to be able to make better decisions. We can achieve this buy tensorflow’s built-in method (more on that later) but, we need to input data into the neural network. We could pass the entire deque to it, but it is undesirable, because deque will hold (preferably 1000 or more) experiences and, by no means, the NNs input layer is 1000 nodes in the structure that I use. So we need to sample the dataset randomly to get a training batch of experiences that will be passed into the NN later on. We make a random index array with our desired batch-size, then using a loop, get items in each key and save them to a numpy array, finally, we convert the numpy ndarrays to tensorflow tensors for better compatibility.
def sample(self, miniBatchSize:int) -> tuple:
"""
Get a random number of experiences from the entire experience memory.
The memory buffer is a double ended queue (AKA deque) of named tuples. To make
this list usable for tensor flow neural networks, this each named tuple inside
the deque has to be unpacked. we use a iterative method to unpack. It may be
inefficient and maybe using pandas can improve this process. one caveat of using
pandas tables instead of deque is expensiveness of appending/deleting rows
(experiences) from the table.
Args:
miniBatchSize: int: The size of returned the sample
Returns:
A tuple containing state, action, reward, nextState and done
"""
miniBatch = random.sample(self.exp, miniBatchSize)
state = tf.convert_to_tensor(np.array([e.state for e in miniBatch if e != None]), dtype=tf.float32)
action = tf.convert_to_tensor(np.array([e.action for e in miniBatch if e != None]), dtype=tf.float32)
reward = tf.convert_to_tensor(np.array([e.reward for e in miniBatch if e != None]), dtype=tf.float32)
nextState = tf.convert_to_tensor(np.array([e.nextState for e in miniBatch if e != None]), dtype=tf.float32)
done = tf.convert_to_tensor(np.array([e.done for e in miniBatch if e != None]).astype(np.uint8), dtype=tf.float32)
return tuple((state, action, reward, nextState, done))
Necessary Methods
We need some functions to run the loop that we take iterative steps. We will talk about them here. Before diving deep into coding, we need to set something straight. There aren’t many references about this on the net. In our DQN, we don’t know the values of Q initially. One way to solve this is to have two neural networks. One network for predicting the Q values with high rate of change (Called the Q-Network) and, a second network for outputting the target values so the Q-Network would have something to learn from (Referred to as target-Q-Network). These two networks have identical architectures and, at the beginning, the start with the same weights. However, it is essential to know that the target network shouldn’t change rapidly as the Q-Network. Because, if it did, the Q-Network wouldn’t have enough time to converge to a rapidly changing value. This problem can be solved in two ways:
- Change the target-Q-Network only after C time steps. Because that C is a constant that changes from problem to problem, we have to acquire the suitable C constant with trial and error. Also, Note that C is in time steps, not episodes.
- Use method of soft updating for updating the target-Q-Network. In the equation below, Tau is a very small number.
In the current work, we have used both methods simultaneously. OK, Back to coding!
For computing the loss, we use the function below. The function below, computes the loss between the two mentioned networks (target-Q-Network and Q-Network ). We have used Tensorflow’s mean squared error function to calculate the difference between two outputs. For a more detailed explanation of how the loss is calculated for each network, refer to the comments of this method.
def computeLoss(experiences:tuple, gamma:float, qNetwork, target_qNetwork):
"""
Computes the loss between y targets and Q values. If the reward of current step is R_i,
then y = R_i if the episode is terminated, if not, y = R_i + gamma * Q_hat(i+1) where gamma
is the discount factor and Q_hat is the predicted return of the step i+1 with the target_qNetwork.
Args:
experiences: Tuple: A tuple containing experiences as tensorflow tensors.
gamma: float: The discount factor.
qNetwork: tensorflow NN: The neural network for predicting the Q.
target_qNetwork: tensorflow NN: The neural network for predicting the target-Q.
Returns:
loss: float: The Mean squared errors (AKA. MSE) of the Qs.
"""
# Unpack the experience mini-batch
state, action, reward, nextState, done = experiences
# To implement the calculation scheme explained in comments, we multiply Qhat by (1-done).
# If the episode has terminated done == True so (1-done) = 0.
Qhat = tf.reduce_max(target_qNetwork(nextState), axis=-1)
yTarget = reward + gamma * Qhat*((1 - done))
qValues = qNetwork(state)
qValues = tf.gather_nd(qValues, tf.stack([tf.range(qValues.shape[0]), tf.cast(action, tf.int32)], axis=1))
loss = tf.keras.losses.MSE(yTarget, qValues)
return loss
Now about updating the weights of the NNs, remember at the beginning of this section we talked about soft updates in this networks? yeah, below I have coded it so you wont have to! Because we use tf.function in this project, we cant use get_weight() or set_weight() functions. to update the model weights. This is due to the fact that the previous functions use numpy in their structures which is not supported while generating tensorflow graphs. So to update the weights, we have to iterate through each and every one and replace them in a loop which is not ideal (performance-wise). As you can see, we have chosen a very small value for the updating process (0.001) to let the Q-Network converge better. If you found any alternatives to this approach, please let me know as well!
def softUpdateNetwork(qNetwork, target_qNetwork, Tau: float):
"""
Update the target_qNetwork's weights using soft update, This helps the target network to avoid
changing very rapildy as qNetwork is updated. This increases the learning stability greatly.
The formulation is as follows:
W_targetNetwork = W_targetNetwork * (1 - Tau) + Tau * W_qetwork
Args:
qNetwork, target_qNetwork: Tensorflow networks: Self explanatory.
Tau: float: The soft update parameter, Tau << 1
"""
# Below is a way to update the weights in batches but can only be used
# if we are doing the calculations in eager mode.
# Can't use hte code below!!!!
# W_target = np.array(target_qNetwork.get_weights(), dtype=object)
# w_qNetwork = np.array(qNetwork.get_weights(), dtype=object)
# W_target = (1-Tau) * W_target + Tau * w_qNetwork
# target_qNetwork.set_weights(W_target)
for target_weights, q_net_weights in zip(target_qNetwork.weights, qNetwork.weights):
target_weights.assign(Tau * q_net_weights + (1.0 - Tau) * target_weights)
To implement the training process (i.e. updating the weights), we use GradientTape method. tensorflow’s native train function is uses this method as well, but here, we have chosen this approach to be able to customize the training process (Which is imperative). As you can see, decorated the primary function with tf.function() which helps us in terms of application performance and speed. For more information, see here.
@tf.function()
def fitQNetworks(experience, gamma, qNetwork, target_qNetwork, optimizer):
"""
Updates the weights of the neural networks with a custom training loop. The target network is
updated my a soft update mechanism.
Args:
experience: tuple: The data for training networks. This data has to be passed with
replayMemory.sample() function which returns a tuple of tensorflow tensors in
the following order: state, action, reward, nextState, done)
gamma: flaot: The learning rate.
qNetwork, target_qNetwork: tensorflow NNs
optimizer: tf.keras.optimizers.Adam: The optimizer for updating the networks.
Returns:
None
"""
with tf.GradientTape() as tape:
loss = computeLoss(experience, gamma, qNetwork, target_qNetwork)
grad = tape.gradient(loss, qNetwork.trainable_variables)
optimizer.apply_gradients(zip(grad, qNetwork.trainable_variables))
softUpdateNetwork(qNetwork, target_qNetwork, .001)
To get the next action in each state, we use an epsilon greedy approach. In this example (lunar lander) we have four actions (hence 4 states). In the cartpole example, we only have two actions in each state (move right or left). This function is one of the few functions that has to be customized for each environment. In the lunar lander, entire action state is [0, 1, 2, 3]. With a probability of epsilon, a random choice will be picked, else the action with the greatest Q value will be chosen. Also, note that in the code block below, a function for decaying the epsilon is coded as well. At the beginning of the learning process, we need leave no stone unturned, to be able find better Q values; however, as we complete the Q table, we have to lower the amount of randomness of our search process. To this end, in the beginning of the process, epsilon starts with 1 which indicates that the agent completely acts on a random basis (AKA Exploration) but as the learning is continued, the rate at which agent acts randomly is decreased via multiplying the epsilon by a decay rate which ensures agent acting based on it’s learning
(AKA Exploitation).
def getAction(qVal: list, e:float) -> int:
"""
Gets the action via an epsilon-greedy algorithm.
Args:
qVal: list: The q value of actions
e: float: The epsilon which represents the probability of a random action
Returns:
action_: int: 0 for doing nothing, and 1 for left thruster, 2 form main thruster
and 3 for right thruster.
"""
rnd = random.random()
# The actions possible for LunarLander i.e. [DoNothing, leftThruster, MainThruster, RightThruster]
actions = [0, 1, 2, 3]
if rnd < e:
# Take a random step
action_ = random.randint(0,3)
else:
action_ = actions[np.argmax(qVal)]
return action_
def getEbsilon(e:float, eDecay:float, minE: float) -> float:
"""
Decay epsilon for epsilon-Greedy algorithm.
Args:
e: float: The current rate of epsilon
eDecay: float: The decay rate of epsilon
minE: float: the minimum amount of epsilon. To ensure the exploration possibility of the
agent, epsilon should't be less than a certain amount.
Returns: epsilon's value
"""
return max(minE, eDecay * e)
If you remember, I said we chose both “soft update” and “updating every C steps” to update the network(s). The code below, determines if an update for networks is necessary.
def updateNetworks(timeStep: int, replayMem: ReplayMemory, miniBatchSize: int, C: int) -> bool:
"""
Determines if the neural network (qNetwork and target_qNetwork) weights are to be updated.
The update happens C time steps apart. for performance reasons.
Args:
timeStep: int: The time step of the current episode
replayMem: deque: A double edged queue containing the experiences as named tuples.
the named tuples should be as follows: ["state", "action", "reward", "nextState", "done"]
Returns:
A boolean, True for update and False to not update.
"""
return True if ((timeStep+1) % C == 0 and miniBatchSize < replayMem.len) else False
The Main Code
Here we use all the coded methods to make the RL process. First, we have to import the necessary methods, and amke the gymnasium environment
import gymnasium as gym import tensorflow as tf from collections import deque from collections import namedtuple import numpy as np import matplotlib.pyplot as plt from tqdm import tqdm import time import copy import pandas as pd import matplotlib import math import random import imageio
For making the environments, you can use the following codes. Note that they are slightly different.
Lunar Lander – V2
# Making the environment - LunarLander
env = gym.make("LunarLander-v2") # Use render_mode = "human" to render each episode
state, info = env.reset() # Get a sample state of the environment
stateSize = env.observation_space.shape # Number of variables to define current step
nActions = env.action_space.n # Number of actions
nObs = len(state) # Number of features
Cartpole
# Making the environment - CartPole
env = gym.make("CartPole-v1") # Use render_mode = "human" to render each episode
state, info = env.reset() # Get a sample state of the environment
stateSize = env.observation_space.shape # Number of variables to define current step
nActions = env.action_space.n # Number of actions
nObs = len(state) # Number of features
Next, we make the neural networks (the backbone of the learning process). As mentioned, we have to make two identical networks. The network is a simple one, with 64 units in the first and second layers. The output layer’s length is 4 for lunar lander and 2 for cartpole environment. The activation function of the layers are ReLu, ReLu and, Linear respectively.
# Making the neural networks # Specifying the optimizer. optimizer = tf.keras.optimizers.Adam(.001) # Because of the binary structure of the actions possible (Step to right or left) we have # added a taken a sigmoid activation for the output layer. # The q-Network inputs = tf.keras.layers.Input(shape=stateSize) l1 = tf.keras.layers.Dense(units=64, activation="relu", name = "L1")(inputs) l2 = tf.keras.layers.Dense(units=64, activation="relu", name = "L2")(l1) output = tf.keras.layers.Dense(units=nActions, activation="linear", name = "out")(l2) qNetwork = tf.keras.Model(inputs = inputs, outputs = output, name = "q-network") # The Target q-Network target_inputs = tf.keras.layers.Input(shape=stateSize) target_l1 = tf.keras.layers.Dense(units=64, activation="relu", name = "L1")(target_inputs) target_l2 = tf.keras.layers.Dense(units=64, activation="relu", name = "L2")(target_l1) target_output = tf.keras.layers.Dense(units=nActions, activation="linear", name = "out")(target_l2) target_qNetwork = tf.keras.Model(inputs = target_inputs, outputs = target_output, name = "target-q-network") # Both qnetwork and target-qnetworks's weights are initialized but at the ebginning # the two networks should have the same weights. target_qNetwork.set_weights(qNetwork.get_weights())
And finally, the beating heart of the RL process, the training loop: As you can see, a lot happens in the code block below. In the first part of the code, we take care of the primary variables that the process is based upon. Each variable is explained with inline comments. The learning happens inside a loop that continues until the number of learning episodes reached (500 here), or the desired score is reached. the desired score for the learning differs from environment to environment. Referring to the documentation of the gymnasium library, 200 and 475 are the scores at which we can confidently say that the agent has learnt the process well for the lunar lander and cartpole agents, respectively. Also, please note that by the word “score”, I mean the average score of the last 100 episodes. Having the average score as a criteria for the learning quality, helps with the robustness of the outcomes.
Inside the episode loop, there is another loop that processes time steps in each episode. The loop will continue until its terminated or truncated. On an important note, DO KNOW that the learning takes place with respect to time steps, not episodes. Also, to change the score that we are aiming for (so the learning stops), refer to line 99.
# Start the timer
tstart = time.time()
# The experience of the agent is saved as a named tuple containing variouse variables
agentExp = namedtuple("exp", ["state", "action", "reward", "nextState", "done"])
# Parameters
nEpisodes = 2000 # Number of learning episodes
maxNumTimeSteps = 1000 # The number of time step in each episode
gamma = .995 # The discount factor
ebsilon = 1 # The starting value of ebsilon
ebsilonEnd = .1 # The finishing value of ebsilon
eDecay = 0.995 # The rate at which ebsilon decays
miniBatchSize = 100 # The length of minibatch that is used for training
memorySize = 100_000 # The length of the entire memory
numUpdateTS = 4 # Frequency of timesteps to update the NNs
numP_Average = 100 # The number of previouse episodes for calculating the average episode reward
# Variables for saving the required data for later analysis
episodePointHist = [] # For saving each episode's point for later demonstration
episodeTimeHist = [] # For saving the time it took for episode to end
actionString = "" # A string containing consecutive actions taken in an episode (dellimited by comma, i.e. 1,2,4,2,1 etc.)
episodeHistDf = pd.DataFrame(columns=["episode", "actions", "seed", "points"])
initialCond = None # initial condition (state) of the episode
# Making the memory buffer object
mem = ReplayMemory(size=memorySize)
for episode in range(nEpisodes):
initialSeed = random.randint(1,1_000_000_000) # The random seed that determines the episode's I.C.
state, info = env.reset(seed = initialSeed)
points = 0
actionString = ""
initialCond = state
tempTime = time.time()
for t in range(maxNumTimeSteps):
# We use teh __call__ function instead of predict() method because the predict()
# function is better suited (faster) for batches of data but we here only have
# a single state to predict.
qValueForActions = qNetwork(np.expand_dims(state, axis = 0))
# use ebsilon-Greedy algorithm to take the new step
action = getAction(qValueForActions, ebsilon)
# Take a step
observation, reward, terminated, truncated, info = env.step(action)
# Store the experience of the current step in an experience deque.
mem.addNew(
agentExp(
state, # Current state
action,
reward, # Current state's reward
observation, # Next state
True if terminated or truncated else False
)
)
env.render()
# Check to see if we have to update the networks in the current step
update = updateNetworks(t, mem, miniBatchSize, numUpdateTS)
if update:
# Update the NNs
experience = mem.sample(miniBatchSize)
fitQNetworks(experience, gamma, qNetwork, target_qNetwork, optimizer)
# Save the necessary data
points += reward
state = observation.copy()
actionString += f"{action},"
if terminated or truncated:
# Save the episode histry in dataframe
if (episode+1)%10 == 0:
# only save every 10 episodes
episodeHistDf = pd.concat([episodeHistDf, pd.DataFrame({
"episode": [episode],
"actions": [actionString],
"seed": [initialSeed],
"points": [points]
})])
break
# Saving the current episode's points and time
episodePointHist.append(points)
episodeTimeHist.append(time.time()-tempTime)
# Getting the average of {numP_Average} episodes
epPointAvg = np.mean(episodePointHist[-numP_Average:])
# Decay ebsilon
ebsilon = decayEbsilon(ebsilon, eDecay, ebsilonEnd)
print(f"\rElapsedTime: {(time.time() - tstart):.0f}s | Episode: {episode} | The average of the {numP_Average} episodes is: {epPointAvg:.2f}", end = " ")
if 200 < epPointAvg:
Tend = time.time()
print(f"\nThe learning ended. Elapsed time for learning: {Tend-tstart}s")
break
# Reset the index
episodeHistDf.reset_index(drop=True, inplace=True)
env.close()
Results
Now comes the fun part! we will check the learning process for each environment in stages with various scores to see how the RL agent works.
Cartpole
AVG Score: 200
AVG Score: 50
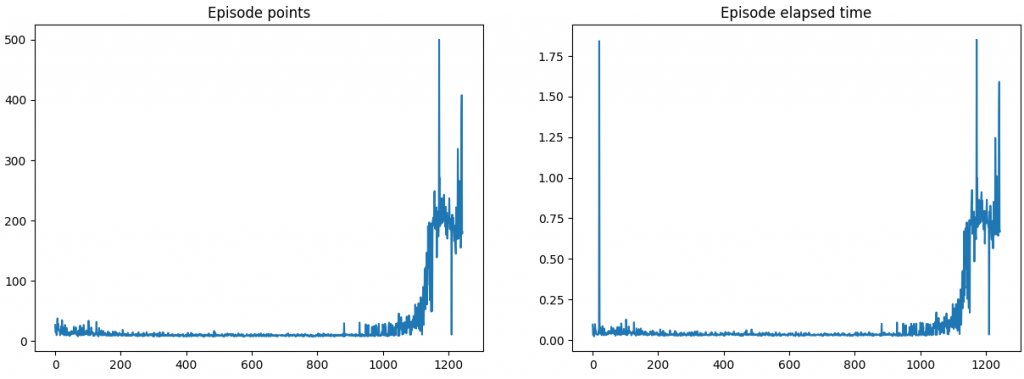
Each episode’s point and elapsed time as the the learning progresses
Lunar lander
AVG Score: 200
AVG Score: 50
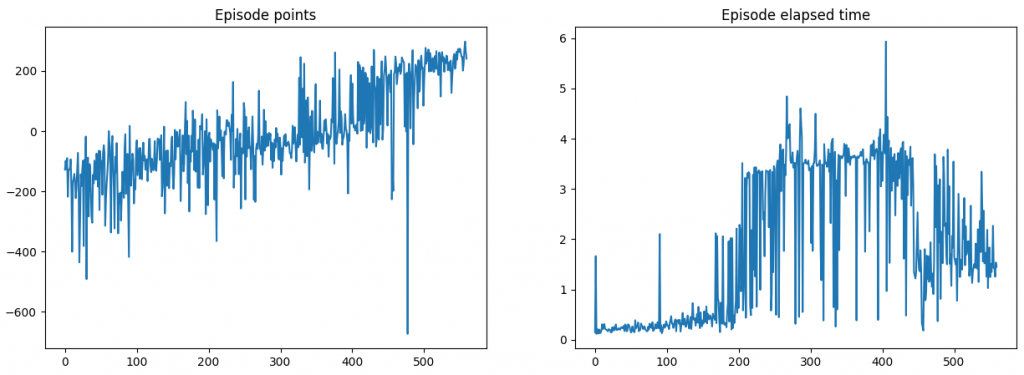
Each episode’s point and elapsed time as the the learning progresses
On a side note, you can use the code below to visualize how RL works in your environment. For example, visualizing the cartpole-v1 environment on a fully learnt neural is stated below. It also saves the results in a gif file as well.
def testAgent(envName:str, network, saveVideoName:str = "") -> int:
"""
Runs an agent through a predefined gymnasium environment. The actions of the agent are chosen via
a greedy policy by a trained neural network. To see the agent in action, the environment's render
mode has to be "human" or "rgb-array"
Args:
envName: string: The name of the environment.
network: tensorflow NN: The trained neural network that accepts state as an input and outputs
the desired action.
environment: gymnasium env: The environment for testing.
saveVideoName:string: The name of the file to be saved. If equals "", No video file will be
saved; Also remember that the file name should include the file extension.
"""
def interactionLoop(env_, seed_, V_):
"""
The loop that lets agent interact with the environment.
if V_ == True, save the video (requires render_mdeo == rgb_array)
"""
state, _ = env_.reset(seed = seed_)
points = 0
if V_:
videoWriter = imageio.get_writer(saveVideoName, fps = 30)
maxStepN = 1000
for t in range(maxStepN):
# Take greedy steps
action = np.argmax(network(np.expand_dims(state, axis = 0)))
state, reward, terminated, truncated, _ = env_.step(action)
if V_:
videoWriter.append_data(env_.render())
points += reward
# Exit loop if the simulation has ended
if terminated or truncated:
_, _ = env_.reset()
if V_:
videoWriter.close()
return points
# Get the random seed to get the initial state of the agent.
seed = random.randint(0, 1_000_000_000)
# Because gymnasium doesn't let the environment to have two render modes,
# we run the simulation twice, The first renders the environment with "human"
# mdoe and the secon run, runs the environment with "egb_array" mode that
# lets us save the interaction process to a video file. Both loops are run
# with the same seeds and neural networks so they should have identical outputs.
environment = gym.make(envName, render_mode = "human")
point = interactionLoop(environment, seed, False)
environment = gym.make(envName, render_mode = "rgb_array")
point = interactionLoop(environment, seed, True)
return point
testAgent("CartPole-v1", qNetwork, "data/cartPole-200.gif")