
Making a Data Generator For Tensorflow

When you are trying to train your Neural Network with large amounts of data, It is not feasible to load all of the training data at once; because you might face problems with your RAM. A solution to alleviate this problem would be to load the training data in separate batches. With this method, we train the neural network with a single batch, after the weights are updated, we remove the loaded images from RAM, and consequently, load the new batch. We continue this until we have loaded all the training data.
In the Tensorflow documentation, this is noted as “Parallel Dataset”. You can learn about this in the following link; however; if you don’t feel like reading it, DON’ WORRY, I GOT YOU! Every parallel dataset should implement two methods: __getitem__() and __len__(). Optionally, if you want a method to run at the end of each epoch, you can name that method on_epoch_end(). The method __getitem__() should return a complete batch; it will accept only one argument (besides the self) which defines the batch index. As stated in Tensorflow documentation, using this method guarantees that the network will only train once on each sample per epoch.
Furthermore, the second necessary method, __len__(), should return the number of batches per epoch.
With all the necessary information, now lets make a class for generating necessary data and feeding them in batches to our network! We have written code for YOLOv1 network but don’t worry if you are unfamiliar with this network, 95% of the code is written so that it can be used for any purposes and network. And the remaining 5% will be explained so that you can easily understand it and change it so that it could fit your own network.
The code below defines dataGenerator_YOLOv1 class and initializes it. The __init__ method is fully commented and is self-explanatory. At the end of __init__, we search the directory that contains the training data to get the image IDs, preferably, each image’s ID should be denoted at its name (e.g. {image_name}.{extension}); however; you can also save the IDs in a text file and read it. At the end of __init__, we run the on_epoch_end() method once. This method is tasked with updating the indexes after each epoch ends, more on this method later!
class dataGenerator_YOLOv1(keras.utils.Sequence):
"""
The dataGenerator class is used to help with the loading of training data to tensorflow model.
"""
def __init__(self, trainImgDir, batchSize, imgSize, annotDf, nClass, shuffle):
"""
Initializes the object.
Args:
trainImgDir: str: The directory which contains the training data. Each file should be saved with
jpg extension. Also the imageId of each training sample should be the same as its file name.
e.g. {imageId}.gpg
batchSize: int: The size of training samples in each batch. Preferably powers of two.
annotDf: pd.Dataframe: A pandas directory containing all of the annotations.
imgSize: tuple: A tuple containing training image size (width,height) in pixels. (448,448) for
YOLOv1.
nClass: int: Number of classes that are to be detected.
shuffle: bool: Weather to shuffle the data at the end of each epoch.
"""
self.trainDir = trainImgDir
self.imgSize = imgSize
self.batchSize = batchSize
self.annots = annotDf
self.nClass = nClass
self.shuffle = shuffle
self.indexes = np.array([])
self.lstImageId = [] # A list of entire training image ids
# Search the trainDir to acquire all the image IDs
__lst = os.listdir(trainImgDir)
__lst = [item for item in __lst if item.endswith(".jpg")]
__lst = [tmp.replace(".jpg", "") for tmp in __lst]
self.lstImageId = __lst
# Run once when object is created.
self.on_epoch_end()
The mandatory method __len__() returns the number of batches in each epoch (An epoch means training the neural network with all the training data for one cycle). All the image IDs are stored in lstImageId list, so the number of batches can be easily attained by dividing the number of all training images to each batch’s size and rounding it to the nearest bigger integer.
def __len__(self):
"""
As stated in tensorflow documentation, should return the number of batches per epoch
"""
return int(len(self.lstImageId) / self.batchSize)
The mandatory method __getitem__() returns a training batch, the batch is chosen using idx variable. The choosing logic goes like this: self.indexes contains indexes from 0 to len(self.lstImageId). At the end of each epoch the index list may be shuffled. Using the index argument, Tensorflow iterates through batches. We select the proper chunk of self.indexes using the index argument then we fill lstIDs with self.lstImageId items using the indexes we acquired.
The we generate the training batch with __generateBatch() method. x and y stand for the training images and their respective truth values. Each of x and y should be numpy arrays and we have developed this code to fit the YOLOv1 neural network structure. The __generateBatch() gets a list of image IDs and using __read() method, reads every image and appends the image and its respective truth value as a numpy array and adds it to a temporary list. All the seemingly incoherent code inside the __read() method are for generating the necessary truth value; you can change it to fit your own purpose. however; the first 4 lines are for processing the train image and normalizing it which should be left as it is!
def __getitem__(self, idx):
"""
This method generates batches. The right batch should be chosen by using the index argument.
The logic: self.indexes contains indexes from 0 to len(self.lstImageId) at the end of each
epoch the index list may be shuffled. Using the index argument, tensorflow iterates through
batches. We select the proper chunk of self.indexes using the index argument then we fill
lstIDs with self.lstImageId items using the indexes we acquired.
"""
__indexes = self.indexes[self.batchSize * idx : self.batchSize * (idx+1)]
lstIDs = [self.lstImageId[i] for i in __indexes]
# Generate the batch
x,y = self.__generateBatch(lstIDs)
return x,y
def __generateBatch(self, lstImg):
"""
Generates a batch by iterating through a list of image IDs.
Args:
lstImg: list: A list of strings, containing image IDs.
Returns:
A batch of training and ground truth data.
"""
x = []
y = []
for id in lstImg:
img, tensor = self.__read(id)
x.append(img)
y.append(tensor)
return np.array(x), np.array(y)
def __read(self, ID):
"""
Read the images and generate the ground truth tensor from annotations.
First the image is read, resized and normalized, Then the annotations from the previously
acquired dataframe is used to generate the ground truth tensor.
For YOLOv1 each image is divided to 7*7 grids and each grid cell has the following parameter
in (order is important): [confScore, relX, relY, width, height, <classes one-hot vector>].
where relX and relY define the center of the bounding box relative to the grid cell. width
and height parameters define the width and height of the bounding box relative to the
entire image (They are NOT relative to the bounding box to avoid acquiring numbers bigger
than 1).
Args:
ID: str: ID of the image to read
Returns:
Two numpy arrays, The normalized image and it's ground truth tensor compatible with YOLOv1
architecture.
"""
imgDir = f"{self.trainDir}/{ID}.jpg"
# Read, resize and normalize the image
img = Image.open(imgDir)
img = img.resize(self.imgSize)
img = np.array(img)/255.
# Generate the ground truth tensor
outTensor = np.zeros((7,7,1*5 + self.nClass))
# Get the relevant annotations
df = self.annots[self.annots.id == ID]
for _, row in df.iterrows():
# Get the absolute values for x,y,w and h
x = row.boxCenterX * 448
y = row.boxCenterY * 448
w = row.boxWidth * 448
h = row.boxHeight * 448
# Get the x and y indexes of the grid cell
cell_idx_i = int(x / 64) + 1
cell_idx_j = int(y / 64) + 1
# The top-left corner of the gridCell
x_a = (cell_idx_i-1) * 64
y_a = (cell_idx_j-1) * 64
# The relative coordinates of the bounding box to the gridcell's top-left
# corner except w and h which are relative to the entire image.
xRel = (x-x_a) / 64
yRel = (y-y_a) / 64
wRel = w / 448
hRel = h / 448
# Change the output matrix accordingly. The target tensor/matrix should have
# the following properties for each grid cell: (confidenceScore|xRel|yRel|w|h|classNo)
# where the classNo is a one-hot encoded vector.
outTensor[cell_idx_i-1,cell_idx_j-1,:] = np.array([1, xRel, yRel, wRel, hRel,1])
return img, outTensor
And finally, for the optional method on_epoch_end() we have the following code. if shuffle is true, numpy is used to shuffle the image indexes. Bear in mind that the shuffling happens only at the end of each epoch and, in the midst of a training epoch, the image indexes is left unchanged.
def on_epoch_end(self):
"""
Updates the indexes after each epoch. If self.shuffle == True, the training indexes will be shuffled.
"""
self.indexes = np.arange(len(self.lstImageId))
if self.shuffle == True:
np.random.shuffle(self.indexes)
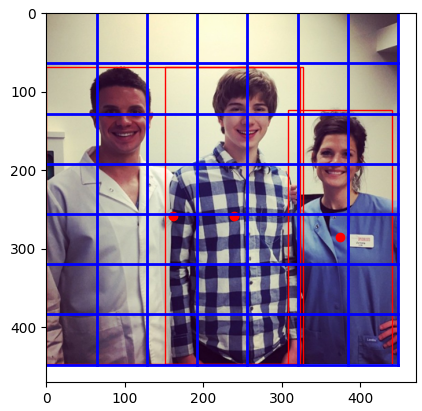
To see how our code works, we will use our code to generate a single batch of 1 image, with its respective annotations. To prepare our dataset, we will use Fiftyone library (Data acquisition) and couple of custom functions. I will not elaborate on these methods, because they are fairly straight forward, and as always, completely documented.
def annotationsToDataframe(annotDir, annotExt, annotId = None):
"""
Reads the annotations from a directory and returns a dataFrame. Annotations can be saved
in two formats: TXT or XLS.
TXT: The annotations saved in text files should contain a single detection in each
line. Every line should be in the following order: [className rel_x rel_y width height].
Where rel_x and rel_y are the coordinates of the center of the bounding box relative to
the entire picture and width and height of the box are also relative the entre picture.
XLS: ----TODO----
Note that it is assumed that the ID of each annotation is the file's name and there should
be and image file with the same exact name (And different extension) in the data directory.
Args:
annotDir: str: The directory containing annotations.
annotExt: str: The extensions of the annotations.
annotId: str: The id of the specific image. If you want the returned dataFrame to contain only
the annotations for a specific image. If None, the entire annotation directory will
be read and returned as a dataFrame.
Returns:
A pandas dataFrame with columns: [id, boxCenterX, boxCenterY, boxWidth, boxHeight, objClass]
"""
# For performance purposes, we wont use append/concat row methods for each new entry. We append
# new data to lists as we iterate through the annotations. At the end we make a dataFrame with
# the lists in hand.Temporary lists for appending the new data.
__lstID = []
__lstBoxCenterX = []
__lstBoxCenterY = []
__lstBoxWidth = []
__lstBoxHeight = []
__lstClass = []
if annotExt.lower() == "txt":
# Read the files in the directory
files = glob.glob(f"{annotDir}/*.txt")
for file in files:
# GEt the annotation ID which is the file name
__fName = Path(file).stem
# Only get a specific annotation. IF else, get all the annotations.
if annotId != None:
if __fName != annotId:
continue
with open(file) as f:
for annot in f.readlines():
annot = annot.replace("\n","") # Replace newline character
annot = annot.split(" ")
# Append the new data
__lstID.append(__fName)
__lstBoxCenterX.append(float(annot[1]))
__lstBoxCenterY.append(float(annot[2]))
__lstBoxWidth.append(float(annot[3]))
__lstBoxHeight.append(float(annot[4]))
__lstClass.append(int(annot[0]))
elif annotExt.lower() == "xml":
# ----TODO----
pass
else:
print("Invalid extension type. Only text and XML files are acceptable.")
# Make a data generator object and get a single item
a = dataGenerator_YOLOv1(f"{os.getcwd()}/data/images/train", 1, (448,448), df, 1, True)
x,y = a.__getitem__(0)
u = np.int16(x[0,:]*255)
v = y[0,:]
fig, ax = plt.subplots()
ax.imshow(u)
gridCells = (7,7)
# Add the grid cells to matplotlib chart
if gridCells != None:
# Adding the horizontal lines
for i in range(gridCells[1]):
ax.plot([0, 448], [448*(i+1)/gridCells[1],448*(i+1)/gridCells[1]], color = "blue", linewidth = 2)
# Adding the vertical lines
for i in range(gridCells[0]):
ax.plot([448*(i+1)/gridCells[0],448*(i+1)/gridCells[0]], [0, 448], color = "blue", linewidth = 2)
# Add the annotations to the plot
for i in range(7):
for j in range(7):
if v[i,j,0] != 0:
ax.scatter(i * 64 + v[i,j,2]*64, j * 64 + v[i,j,3]*64, c="red")
xC = i * 64 + v[i,j,2]*64
yC = j * 64 + v[i,j,3]*64
ww = 448 * v[i,j,4]
hh = 448 * v[i,j,5]
ax.add_patch(patches.Rectangle((xC - ww/2,yC - hh/2),ww,hh, fill = None, color = "red"))
plt.show()
As you can see, We have three “Person”s detected in the image using the annotations.
This marks the end of this training. Hope this data generator helps you! To see the coded data generator in action, you can see my posts on object detection in this blog.