
YOLOv1: All you need to know & Its code

In this post we will construct the famous YOLOv1 neural network. It stands for “You Only Look Once” and at the time it was first introduced, it performed much better than its competitors in terms of detection speed and accuracy. YOLOv1 was introduced in 2015 by Redmon et al. you can see the original paper here. Bear in mind that, in the following post, we have taken that you have a solid knowledge about neural networks and a basic knowledge about machine vision.
Data acquisition
First, to train our network, we need a large amount of images that have been annotated. We will use Fiftyone library to this end. You can see the original documentation here. We will use google’s open images v7. The following code will be used to acquire 1000 samples of images with “Person” annotations for the testing dataset. You can change dsSplit to “train” to the the data necessary for the training dataset as well.
import fiftyone as fo
import fiftyone.zoo as foz
# Download the necessary data and dataset images for testing. We have chosen "open-images-v7-object-detection-DS"
# as the name.
dsName = "open-images-v7-object-detection-DS-test"
dsClasses = ["Person"]
dsSplit = "test"
dsLblTypes = ["detections", "classifications"]
nSamples = 1000
if not fo.dataset_exists(dsName):
dataset = foz.load_zoo_dataset(
"open-images-v7",
split = dsSplit,
label_types = dsLblTypes,
classes = dsClasses,
max_samples = nSamples,
seed = 2,
shuffle = True,
dataset_name = dsName,
)
else:
datasetTest = fo.load_dataset(dsName)
print("Dataset already loaded. ")
Now, the downloaded dataset should be moved to desired directories. It is a common practice to have separate directories for images and their respective labels. Furthermore, each directory (image or label) should contain two sub-directories named train and validation. Because we already know what the desired network is (YOLOv1) and what its parameters are, we don’t need validation dataset. Do know that Fiftyone saved the labels in a JSON file which we will process next.
# Exporting the downloaded datasets to the desired locations.
# Train data
datasetTrain.export(
data_path = "./data/images/train",
labels_path = "./data/labels/train/labels.json",
dataset_type = fo.types.FiftyOneImageDetectionDataset,
classes = dsClasses,
include_confidence = False
)
# Test data
datasetTest.export(
data_path = "./data/images/test",
labels_path = "./data/labels/test/labels.json",
dataset_type = fo.types.FiftyOneImageDetectionDataset,
classes = dsClasses,
include_confidence = False
)
As the final step for data preparation, we deserialize the JSON files in the label folder (train and test sub-directories) to text files. This way, each image’s annotations are located in a text file with image ID as its file name, which is of more convenience. The annotations are saved in the following format: I) Each object’s annotations are noted in a separate ling (e.g. If an image contains two persons, its annotation text file contains two lines of text). II) Annotations are noted by the bounding boxes (which will be explained later). The following information about each object and its bounding box is denoted in the annotation file: {label} {centerX} {centerY} {width} {height}. In the reminder of this article we will explain the bounding boxes and how they work very deeply, don’t worry if you find this last paragraph a little vague!
import json
# Deserialize the json file and convert it to text files to make it compatible with yolov8
# Training dataset
file = open("./data/labels/train/labels.json")
js = json.load(file)
for item in js["labels"]:
txt = ""
with open(f"./data/labels/train/{item}.txt", 'w') as txtFile:
for subItem in js["labels"][item]:
width = subItem["bounding_box"][2]
height = subItem["bounding_box"][3]
centerX = subItem["bounding_box"][0] + width/2
centerY = subItem["bounding_box"][1] + height/2
label = subItem["label"]
txt += f"{label} {centerX} {centerY} {width} {height}\n"
txtFile.write(txt)
txtFile.close()
file = open("./data/labels/test/labels.json")
js = json.load(file)
for item in js["labels"]:
txt = ""
with open(f"./data/labels/test/{item}.txt", 'w') as txtFile:
for subItem in js["labels"][item]:
width = subItem["bounding_box"][2]
height = subItem["bounding_box"][3]
centerX = subItem["bounding_box"][0] + width/2
centerY = subItem["bounding_box"][1] + height/2
label = subItem["label"]
txt += f"{label} {centerX} {centerY} {width} {height}\n"
txtFile.write(txt)
txtFile.close()
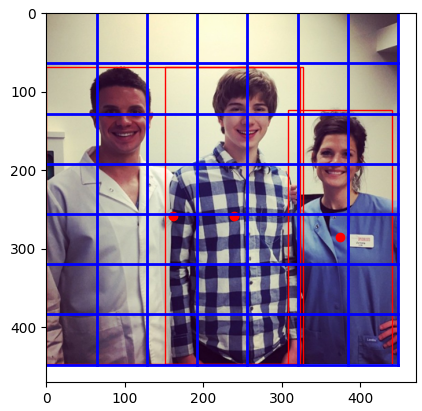
A sample image from the dataset that I downloaded to my own local machine is included below. You can see four “Persons”s in this image. The bounding box of each object is also illustrated. The illustration is implemented via matplotlib which will be explained in the following sections.

How does YOLOv1 work?
YOLOv1 works by dividing the image into a SxS grid. Each grid is tasked with predicting B bounding boxes. Note that each grid can only predict one class, however, B different orientations of bounding boxes for the predicted object is suggested. Five values define a single bounding box: PC, bX, by, bh, bw which respectively, define the confidence level of that particular orientation of the bounding box, the X and Y position of the center of the bounding box and the height and width of that bounding box. These parameters are known as the targets and should be close to the ground truth values. Note that Predicting the object’s location is done with relative absolute values instead of absolute values, to make the training process easier (also called the Label encoding process).
The relative target values for the object from its absolute values are calculated below: Taking (xa,ya) to be the absolute coordinates of the anchor top-left corner (the cell’s) we have xrel = (x-xa)/64, yrel = (y-ya)/64, wrel = w/448, hrel = h/448 Where (x,y,w,h) are the absolute target values of the bounding box. Note that the reason why we do this, is to convert the target values smaller numbers in the (0,1) range. which helps with the training process. Note that the absolute coordinate axes are locates at the picture’s top-left corner (i.e. As we move to the right x increases and as we move to the bottom of the image y increases)
Specifically for YOLOv1, initially the input image is resized into a 448×448 tensor next, the image is divided into 7×7 grid and each grid has a 64×64 shape. As noted in the previous paragraph, each grid cell can only choose one class of object to detect. This means that with YOLOv1, at best, we can detect 49 different objects at the same time. Assuming to have C classes in the training dataset, the output matrix has the following shape: S×S×(B×5+C).
YOLOv1 architecture:
The YOLOv1 architecture is inspired by the GoogleNet model. The network model is consisted of two parts. The first part is called the Back bone which is 24 convolution layers which is used for generating the feature maps. The further layers are used to get the predicting which in YOLOv1 has the shape 7x7x1024 = 50176. In the second part, the back bone output is flattened and the passed to two fully connected layers. with their output is reshaped to a 7x7x30 matrix. The final fully connected layer has 1470 nodes (7730=1470)
| Type | Filters | Size/Stride | Output | |
| Conv | 64 | 7×7 / 2 | 224×224 | |
| Max Pool | 2×2 / 2 | 112×112 | ||
| Conv | 192 | 3×3 / 1 | 112×112 | |
| Max Pool | 2×2 / 2 | 56×56 | ||
| 1× | Conv | 128 | 1×1 / 1 | 56×56 |
| Conv | 256 | 3×3 / 1 | 56×56 | |
| Conv | 256 | 1×1 / 1 | 56×56 | |
| Conv | 512 | 3×3 / 1 | 56×56 | |
| Max Pool | 2×2 / 2 | 28×28 | ||
| 4× | Conv | 256 | 1×1 / 1 | 28×28 |
| Conv | 512 | 3×3 / 1 | 28×28 | |
| Conv | 512 | 1×1 / 1 | 28×28 | |
| Conv | 1024 | 3×3 / 1 | 28×28 | |
| Max Pool | 2×2 / 2 | 14×14 | ||
| 2× | Conv | 512 | 1×1 / 1 | 14×14 |
| Conv | 1024 | 3×3 / 1 | 14×14 | |
| Conv | 1024 | 3×3 / 1 | 14×14 | |
| Conv | 1024 | 3×3 / 2 | 7×7 | |
| Conv | 1024 | 3×3 / 1 | 7×7 | |
| Conv | 1024 | 3×3 / 1 | 7×7 | |
| FC | 4096 | 4096 | ||
| Dropout 0.5 | 4096 | |||
| FC | 7×7×30 | 7×7×30 |
1. Model
1.1 Tensorflow Model
Ok! Now lets start coding YOLOv1 and train it. We will begin by coding the actual network architecture. Before I start explaining the model implementation, I have to say that, as you can see, we have imported a class (YOLOv1_LastLayer_Reshape) and a function (YOLOv1_loss) which are essential for coding the YOLOv1 model. I will elaborate on them later, for now, just don’t panic! In the code below, we have defined a simple class YOLOV1_Model() which has only a single method getModel() which by being called, will output a Tensorflow model for YOLOv1.
The model architecture is consisted of three parts, namely, (i) Backbone, (ii) Neck and, (iii) Head which, are described below:
- Backbone: A series of convolutional layers that is tasked with extracting and encoding features from the input data. Keep in mind that it is a common practice to pre-train the backbone on a classification dataset for better performance.
- Neck: Neck is responsible for further transforming and refining the features extracted by the backbone model. Its goal is to improve the backbone’s extracted features, and give more informative feature representations.
- Head: The head is made up of task-specific layers that are designed to produce the final prediction or inference based on the information extracted by the Backbone and Neck. In our case, it is called
YOLOv1_LastLayer_Reshapewhich is tasked with reshaping the output of the Neck’s last dense layer, to a new matrix that we can use for loss calculation (more on this later!)
Each part of the network is denoted by a comment. Note that we have used Leaky ReLu for backbone’s activation; however, sigmoid has been used for Neck’s activation. Also, in the neck, a dropout layer is added to avoid over fitting. In the coming parts, we will discuss YOLOv1_LastLayer_Reshape and YOLOv1_loss respectively.
import tensorflow as tf
from YOLOv1_Reshape_Layer import YOLOv1_LastLayer_Reshape
from keras.regularizers import l2 # type: ignore
from YOLOv1_Loss import YOLOv1_loss
class YOLOV1_Model():
def __init__(self):
pass
def getModel(self):
# YOLOv1 structure
YOLOv1_inputShape = (448,448,3) # Shape of the input image
classNo = 1 # Number of classes we are trying to detect
input = tf.keras.layers.Input(shape=YOLOv1_inputShape)
leakyReLu = tf.keras.layers.LeakyReLU(negative_slope = .1)
# The backbone, Acts as a feature extractor
# L1
x = tf.keras.layers.Conv2D(filters = 64, kernel_size=7, strides = 2, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(input)
x = tf.keras.layers.MaxPool2D(pool_size=2, strides=2, padding = "same")(x)
# L2
x = tf.keras.layers.Conv2D(filters = 192, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.MaxPool2D(pool_size=2, strides=2, padding = "same")(x)
# L3
x = tf.keras.layers.Conv2D(filters = 128, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 256, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 256, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 512, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.MaxPool2D(pool_size=2, strides=2, padding = "same")(x)
# L4
for _ in range(4):
x = tf.keras.layers.Conv2D(filters = 256, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 512, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 512, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.MaxPool2D(pool_size=2, strides=2, padding = "same")(x)
# L5
x = tf.keras.layers.Conv2D(filters = 512, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 512, kernel_size=1, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 2, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
# L6
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
x = tf.keras.layers.Conv2D(filters = 1024, kernel_size=3, strides = 1, padding = "same", activation= leakyReLu, kernel_regularizer=l2(1e-5))(x)
# Neck
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(4096)(x)
x = tf.keras.layers.Dense(7*7*(5*2+classNo), activation="sigmoid")(x)
x = tf.keras.layers.Dropout(.5)(x) # Dropout layer for avoiding overfitting
# Head
x = YOLOv1_LastLayer_Reshape((7,7,5*2+classNo))(x)
model = tf.keras.Model(inputs = input, outputs = x, name = "YOLOv1")
model.compile(loss = YOLOv1_loss ,optimizer = 'adam')
return model
1.2 Reshape Layer
To make a custom Tensorflow layer, some rituals are to be taken which you can check out here. Overall, we the layer accepts a single parameter targetShape which, defines the shape of the returned tensor. Bear in mind that this layer is only tasked with reshaping its input, so the input size (7*7*(5*2+classNo)) should match the output shape (7,7,(5*2+classNo)). The input to this layer is the out put of the previous dense and fully connected layer and, the output is a (7,7,(5*2+classNo)) tensor which then will be used for loss calculation.
Where does the this shape come from? Earlier, we said that YOLOv1 divides image to a 7 by 7 grid shape. This is where the two dimensions come from. The third dimension, is where the predicted bounding box is defined. A you remember, when predicting, YOLOv1 predicts two bounding boxes for each grid cell, each bounding box is consisted of 5 parameters [Confidence score, Box center X, Box center Y, Box width, Box height]. Also, I wanna repeat again that, Box center coordinates are floats between 0 and 1, and are relative to the grid cell (64 pixels); whereas, Box width and height are floats between 0 and 1 and, are relative to the entire image (448 pixels).
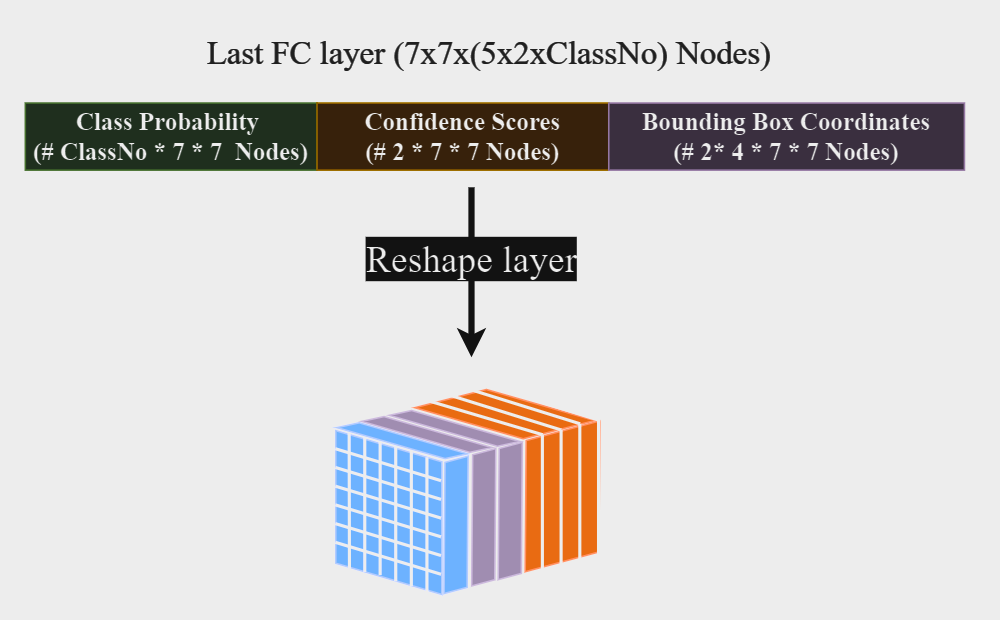
In the picture above, you can see How the reshaping is done.We take the first NumberOfClasses⨯7⨯7 to be the class probabilities, then we reshape it to a (7,7,NumberOfClasses) shape (Denoted by blue color). Second, we take the next 2⨯7⨯7 to be the confidence score of 49 grid cells, remember that each grid cell has 2 predictions and each one has its own confidence score. Then we reshape this second part to a (7,7,2) matrix (colored in lavender). Third, we take the next 2⨯7⨯7⨯4 inputs and reshape them to a (7,7,8) matrix. This part denotes the predicted box coordinates of each grid cell (Colored in orange), Also, throughout this writing, I take it that the first four elements (In the reshaped matrix), denote the first prediction’s coordinates and the second four elements denote the second predicted bounding box. Finally, we concatinate the tree acquired matrices to a one, large matrix with shape (7,7,B*(4+1)+C) where B is the number of bounding boxes for each grid cell, and C is the number of classes that we are trying to find.
On an important side-note, In this article and in my codes, I took C = 1. I took this choice to be able to train my network faster and reduce the complications; however, all of the codes are written in a way that the can be easily generalized for higher C values.
class YOLOv1_LastLayer_Reshape(tf.keras.layers.Layer):
"""
Defines a costume layer for reshaping the last layer to YOLOv1 compatible layer.
Note, No build function is needed.
"""
def __init__(self, targetShape):
"""
Initializes the layer.
"""
super().__init__()
self.targetShape = tuple(targetShape)
def get_config(self):
"""
Helps in serializing the layer data
"""
config = super().get_config()
config.update({"target_shape": self.targetShape})
return config
def call(self, layerInput):
"""
Forward computations. We take the first Sx * Sy * C indexes of each the input
vector to resemble the class probabilities of each grid cell. The rest of the
Sx * Sy * B indexes resemble the confidence scores of each grid cell And the
rest resemble the bounding box parameters <boxCenterX, boxCenterY, width, height>
Args:
layerInput: tensor: The output from a dense (fully connected) layer.
"""
Sx, Sy = self.targetShape[0], self.targetShape[1] # Number of parts that each axis is divided to
C = 1 # Number of classes
B = 2 # Number of predicted bounding boxes per grid cell
# Get the batch size
batchSize = tf.keras.backend.shape(layerInput)[0]
# Class probabilities
classProbs = tf.keras.backend.reshape(layerInput[:,:Sx*Sy*C], (batchSize,) + (Sx,Sy,C))
classProbs = tf.keras.backend.softmax(classProbs) # Run a softmax to choose the right class with highest prob
# Confidence scores
confScores = tf.keras.backend.reshape(layerInput[:,Sx*Sy*C:Sx*Sy*(C+B)], (batchSize,) + (Sx,Sy,B))
confScores = tf.keras.backend.sigmoid(confScores) # Confidence scores should be between 0 and 1
# Bounding boxes
bBox = tf.keras.backend.reshape(layerInput[:,Sx*Sy*(C+B):], (batchSize,) + (Sx,Sy,B*4))
bBox = tf.keras.backend.sigmoid(bBox) # All of the bounding box parameters are relative (Between 0 and 1)
return tf.keras.backend.concatenate([classProbs, confScores, bBox])
# # # Define a simple model using the custom reshaper layer to test it
# # input = tf.keras.layers.Input(shape=(539,))
# # x = YOLOv1_LastLayer_Reshape((7,7,11))(input)
# # model = tf.keras.Model(inputs = input, outputs = x, name = "dummy")
# # model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
# # xTest = np.random.randint(10, size = (1,539))
# # pred = model.predict(xTest)
# # print(pred.shape)
Loss
YOLOv1 uses a custom loss function and, getting to understand (and code) it might be the hardest part to coding YOLOv1 model. I will elaborate on how to write the loss function in detail, so hopefully, you can understand it well and have no questions about it. Firstly, to calculate loss, we need to have a good grasp on a method called IOU (Intersection Over Union). This method is used in YOLOv1, and in other object detection algorithms and is mainly concerned with picking the best predicted bounding box for loss calculation (As you already know, YOLOv1, generates two predictions for each grid cell; however, only one bounding box is needed to calculate the loss). I’m not going to go much deeper about IOU, because it is easy to understand and you can easily get your hand around its implementations with python (See here for more info about IOU). Anyways, below is my custom implementation of IOU.
def iouUtils(boxParams, gridRatio = tf.constant(7, tf.float32)):
"""
Given bounding box centers and its width and height, calculates top-left and bottom-right coordinates of the box.
Note that calculations in this function are done with teh assumption of w and h being a float number, between 0 and 1
with respect to the entire image's size. However, x and y of the bounding box's center are assumed to be a float
between 0 and 1, with respect to the upper-left point of the grid cell.
Args:
boxParams: tf.Tensor: A tensor with following information (Box center X, Box center Y, Box width, Box height) for all
boxes in a tensor.
gridRatio: int: The number of evenly distributed grid cells in each image axis. Use 7 for YOLOv1.
Returns:
Two tensors, one indicating top-left pint of the bBox and, the other one denoting bottom-right edge.
"""
boxXY = boxParams[...,0:2]
halfWH = tf.divide(boxParams[...,2:], tf.constant([2.]))
# Top-left (X, Y) and bottom-right (X, Y)
return tf.subtract(boxXY, halfWH * gridRatio), tf.add(boxXY, halfWH * gridRatio)
def calcIOU(predict_topLeft, predict_bottomRight, truth_topLeft, truth_bottomRight):
"""
Calculates intersection over union for two bounding boxes.
Args:
predict_topLeft, predict_bottomRight: tf.Tensor: Top-left and bottom-right coordinates of the predicted box, acquired
by iouUtils.
truth_topLeft, truth_bottomRight: tf.Tensor: Top-left and bottom-right coordinates of the ground truth box, acquired
by iouUtils.
Returns:
Intersection over union of two boxes
"""
intersectEdgeLeft = tf.maximum(predict_topLeft, truth_topLeft)
intersectEdgeRight = tf.minimum(predict_bottomRight, truth_bottomRight)
intersectWH = tf.abs(tf.subtract(intersectEdgeLeft, intersectEdgeRight))
intersectArea = tf.reduce_prod(intersectWH, axis = -1)
# Get area of predicted and ground truth bounding boxes
predArea = tf.reduce_prod(tf.abs(tf.subtract(predict_topLeft, predict_bottomRight)), axis = -1)
truthArea = tf.reduce_prod(tf.abs(tf.subtract(truth_topLeft, truth_bottomRight)), axis = -1)
# Return IOU
return tf.divide(intersectArea, predArea + truthArea - intersectArea)
Okay, so the YOLOv1 loss is comprised of 3 parts, namely: I) Classification loss, II) Confidence score loss, III) Localization loss. I will each part extensively in this article. Again, I would like to emphasize that YOLO predicts two bounding boxes for each grid cell; however, YOLO only uses one of the predicted bounding boxes in loss calculation, which is the box with the highest IOU.
1. Classification loss
If an object is detected in the box, the classification loss is as follows. Note that ψ is equal to 1, only if there is an object in a respective box, else, it is equal to zero.
2. Localization loss
The localization loss is only calculated for the boxes which have an object. Note that ψ is equal to 1, only if there is an object in a respective box, else, it is equal to zero. Also, w and h are the relative width and height of the bounding box. We do not want to weight absolute errors in large boxes and small boxes equally. i.e. a 2-pixel error in a large box is the same for a small box. To partially address this, YOLO predicts the square root of the bounding box width and height instead of the width and height. Lastly, to emphesize on the bounding box localization loss we multiply the loss by lambda which is equal to 5. The formula is noted below:
3. Confidence loss
The confidence loss is divided to two parts, boxes that have objects and boxes that do not have an object. If there is an object in the box, confidence loss is calculated below. Note that ψ is equal to 1, only if there is an object in a respective box, else, it is equal to zero.
And, if there is no object in the bounding box, confidence loss is calculated below. Most boxes do not contain any objects. This causes a class imbalance problem, i.e. we train the model to detect background more frequently than detecting objects. To remedy this, we weight this loss down by a factor μ which is equal to 0.5.
It might sound strange (and redundant) to account for confidence score loss in boxes that contain no objects; however, this is added to the model to penalize the network for high confidence scores of the cells containing no objects. The cells that have no objects, have a confidence score of 0 in the target ground truth matrix.
The loss function code
The code of the loss function is added here. We use a simple function to define the loss. Per Tensorflow’s instructions, the function should take two arguments, first one is the ground truth data and the second one is the predicted data. We have defined iouUtils and calcIOU in previous sections; however, customSQRT3 will be defined in the end of current section. No worries there!
# YOLOv1 Loss
import tensorflow as tf
from utils import iouUtils, calcIOU, customSQRT3
def YOLOv1_loss(yTrue, yPred):
"""
Runs in the even of loss function calculations
Args:
yTrue, yPred: tf.Tensor: The ground truth value and the predicted value, respectively
Returns:
The calculated loss.
"""
lambdaNoObj = tf.constant(.5)
lambdaCoord = tf.constant(5.)
# Split the predictions and ground truth vectors to coordinates, confidence and class matrices
# 1. Ground truth
idx1, idx2 = 1, 1 + 1
targetClass = yTrue[...,:idx1]
targetConf = yTrue[...,idx1:idx2]
targetCoords = yTrue[...,idx2:]
# 2. Prediction
idx1, idx2 = 1, 1 + 2
predClass = yPred[...,:idx1]
predConf = yPred[...,idx1:idx2]
predCoords = yPred[...,idx2:]
# Get the best bounding boxes by calculating the IOUs
# Note: To to do this process for the confidence scores as well, we concat each box's confidence
# score to its bounding box coordinates and analyze them as a whole.
predBox1 = tf.concat([tf.expand_dims(predConf[...,0],-1),predCoords[...,:4]], axis = -1)
predBox2 = tf.concat([tf.expand_dims(predConf[...,1],-1),predCoords[...,4:]], axis = -1)
# Get the corners of bounding boxes to calculate IOUs
# Note, iouUtils is not coded to accept confidence scores. So we only pass the coordinates into
# it.
p1_left, p1_right = iouUtils(predBox1[...,1:])
p2_left, p2_right = iouUtils(predBox2[...,1:])
t_left, t_right = iouUtils(targetCoords)
# Calculate IOUs for first and second predicted bounding box
p1_IOU = calcIOU(p1_left, p1_right, t_left, t_right)
p2_IOU = calcIOU(p2_left, p2_right, t_left, t_right)
# Get the cells that have objects
maskObj = tf.cast(0 < targetConf, tf.float32)
maskNoObj = tf.cast(0 == targetConf, tf.float32)
# Get mask tensors for boxes that their first prediction has higher IOU
mask_p1Bigger = tf.expand_dims(tf.cast(p2_IOU < p1_IOU, tf.float32),-1)
# Get mask tensors for boxes that their second prediction has higher IOU
mask_p2Bigger = tf.expand_dims(tf.cast(p1_IOU <= p2_IOU, tf.float32),-1)
# Getting the responsible bounding box for loss calculation.
# Output is of shape [...,5] because we disregard the bounding box with smaller IOU
# The first element is the confidence score of that box.
respBox = maskObj*(mask_p1Bigger * predBox1 + mask_p2Bigger * predBox2)
# Calculating the losses
# 1. Classification loss
classificationLoss = tf.math.reduce_sum(tf.math.square(maskObj * tf.subtract(targetClass, predClass)))
# 2. Confidence loss
# Bear in mind, for the boxes with no objects, we account for the confidence loss as well.
# To penalize the network for high confidence scores of the cells containing no objects. The
# cells that have no objects, have a confidence score of 0 in the target ground truth matrix.
# Thus, the loss is calculated as follows: SUM_All_Cells_No_OBJ((C1-0)^2 + (C2-0)^2)
confidenceLossObj = tf.math.reduce_sum(tf.math.square(maskObj * tf.subtract(targetConf, tf.expand_dims(respBox[...,0],-1))))
confidenceLossNoObj = lambdaNoObj * tf.reduce_sum(maskNoObj * tf.reduce_sum(tf.square(predConf), axis = -1, keepdims = True))
# 3. Localization loss
# Bear in mind that respBox is of the shape (...,5) and targetCoords dimension is (...,4)
xyLoss = tf.reduce_sum(tf.square(tf.subtract(respBox[...,1:3], targetCoords[...,0:2])),-1,True)
whLoss = tf.reduce_sum(tf.square(tf.subtract(customSQRT3(respBox[...,3:5], respBox[...,3:5], 10), customSQRT3(targetCoords[...,2:4], targetCoords[...,2:4], 10))),-1,True)
localizationLoss = tf.reduce_sum(lambdaCoord * (xyLoss + whLoss) )
# Sum all the tree types of the errors
return classificationLoss + confidenceLossNoObj + confidenceLossObj + localizationLoss
For the training process, I used Kaggle’s GPUs; however, all of the GPS faced memory overflow when calculating the square root of bounding box height and width. To solve this issue, I coded a custom square root calculator using Babylonian method, which is very well known and is of suitable accuracy for our use.
def customSQRT3(tensor:tf.Tensor, initGuess, iterations:int) -> tf.Tensor:
"""
Returns element-wise estimated square root using Heron's method, also known as babylonian
method.
See: https://en.wikipedia.org/wiki/Methods_of_computing_square_roots
Args:
tensor: tf.Tensor: A tensorflow tensor (All elements should be smaller than 1)
initGuess: tf.float32: The initial guess
iterations: int: Number of iterations, the higher the higher the accuracy of final results
"""
__result = initGuess
for i in range(iterations):
__result = tf.multiply(.5, __result + tf.math.divide_no_nan(tensor, __result))
return __result
Training
To optimize the learning process, we make a custom learning rate that decreases as we proceed with learning.
class customLearningRate(keras.callbacks.Callback):
"""
Sets the learning rate of the fitting process with respect to the epoch number.
Args:
schedule: method: Using the epoch number, returns the suitable learning rate
LR_schedule: list: A list of tuples of epoch number and its respective learning rate value.
If the epoch number of the fitting process doesn't reach the specified epoch number,
the learning rate will remail unchanged. The entries have to be in order of epoch
numbers.
"""
def __init__(self, scheduleFCN, LR_schedule):
"""
Initialized the class
Args:
scheduleFCN: method: A method that returns new learning rate
LR_schedule: list:
"""
super(customLearningRate, self).__init__()
self.LR_schedule = LR_schedule
self.scheduleFCN = scheduleFCN
def on_epoch_begin(self, epoch, logs=None):
"""
Runs on the epoch start.
Args:
epoch: int: The current epoch number.
"""
# # Check to see of the model has defined a learning rate
# if hasattr(self.model.optimizer, "lr"):
# raise Exception("custom learning rate generator: First define a learning rate for the model.")
# Get current learning rate
learningRate = float(tf.keras.backend.get_value(self.model.optimizer.learning_rate))
# Get the new learning rate
newLearningRate = self.scheduleFCN(epoch, self.LR_schedule, learningRate)
# Set the new learning rate as the model's learning rate
self.model.optimizer.learning_rate.assign(newLearningRate)
# Notify the user
if learningRate != newLearningRate:
tf.print(f"Updated the learning rate at epoch NO. {epoch}. New learning rate: {newLearningRate}")
Finally, we use the following code to train our network
# training the network
# To check the GPU status use (if you have a NVIDIA GPU): watch -n 1 nvidia-smi
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint # type: ignore
from utils import lrScheduler
import sys, os
# Import YOLOv1-specific methods and classes
from YOLOv1_Model import YOLOV1_Model
from YOLOv1_learning_Rate import customLearningRate
from YOLOv1_Reshape_Layer import YOLOv1_LastLayer_Reshape
from YOLOv1_Loss import YOLOv1_loss
here = os.path.dirname(".")
sys.path.append(os.path.join(here, '..'))
from dataHandler import *
# Start the training process
if __name__ == "__main__":
# See if there are any GPUs
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
# See if the directory to save the checkpoints exists
if not os.path.isdir(f"{os.getcwd()}/model_data"):
os.mkdir(f"{os.getcwd()}/model_data")
# Instantiate the checkpoint object
chkPoint = ModelCheckpoint(filepath='./model_data/model_{epoch:02d}-{val_loss:.2f}.keras',
save_best_only=True,
monitor='val_loss',
mode='min',
verbose=1
)
batch_size = 1
LR_schedule = [
(0, 0.01),
(75, 0.001),
(105, 0.0001),
]
dfTrain = annotationsToDataframe(f"../data/labels/train", "txt")
trainingBatchGenerator = dataGenerator_YOLOv1(f"../data/images/train", batch_size, (448,448), dfTrain, 1, True)
dfTest = annotationsToDataframe(f"../data/labels/test", "txt")
testingBatchGenerator = dataGenerator_YOLOv1(f"../data/images/test", batch_size, (448,448), dfTrain, 1, True)
model = YOLOV1_Model().getModel()
model.fit(x=trainingBatchGenerator,
steps_per_epoch = int(trainingBatchGenerator.__len__() // batch_size),
epochs = 135,
verbose = 1,
validation_data = testingBatchGenerator,
validation_steps = int(testingBatchGenerator.__len__() // batch_size),
callbacks = [
customLearningRate(lrScheduler, LR_schedule),
chkPoint,
]
)